
The 2017 GPU Technology Conference keynote address by NVIDIA CEO Jensen Huang took place today and focused on the new Tesla Volta V100 as well as the promise of machine learning and artificial intelligence.
https://player.vimeo.com/video/237299421
The growth in this area of the industry is clear. NVIDIA’s conference has grown dramatically over the years, with the number of attendees to the San Jose conference tripling over the last three years. This reflects an increase in the overall number of CUDA developers, which Huang pegged at over 50,000 — a 10x increase over five years ago.
We’ve documented the increase of the use of GPU processing in the visual effects industry, especially as the processing power in GPUs has outpaced that of CPUs. That being said, the growth of the use of GPUs for machine learning, artificial intelligence, and neural networks has increased dramatically in comparison to post.
So while the buzzword today in San Jose was “AI”, there were still many interesting takeaways from the keynote and announcements today including Iray AI, Mental Ray for 3DSMax improvements, and more. The crew at NVIDIA also alluded to vfx and post related announcements coming out closer to SIGGRAPH, which has a greater focus on the industry.
First Volta GPU coming soon

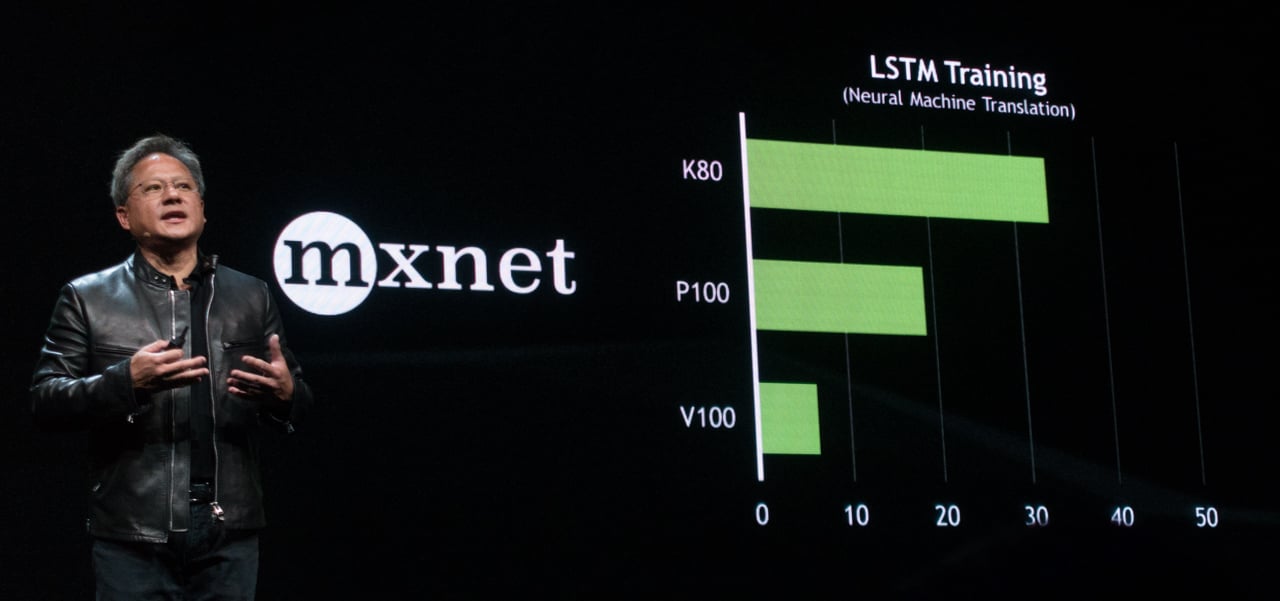
Huang announced the first GPU in NVIDIA’s new Volta architecture, the Tesla V100 Data Center GPU. This is the successor to the “Pascal” architecture, which was announced at last year’s GTC.
The specs are impressive:
- 21 billion transistors in a 12 nanometer manufacturing process
- Overall size 815mm² — about the size of an Apple Watch
- 5,120 CUDA cores
- 7.5 teraflops of processing power for 64-bit floating point operations (CUDA)
- 15 teraflops of processing power for 32-bit floating point operations (CUDA)
- 640 Tensor cores (new cores designed for AI workflows)
- Tensor cores provide 120 teraflops of deep learning performance, effectively equivalent to the performance of 100 CPUs
- 900 GB/sec HBM2 DRAM
- NVLink (card to card inter-connection) now provides 300GB/sec of bandwidth, an increase from Pascal’s 160GB/sec
As a general benchmark, this GPU architecture provides a 1.5x performance improvement for CUDA operations. The 5120 CUDA cores in the V100 compares with 3840 cores in the TITAN Xp or Quadro P6000.
The new Tensor cores are designed specifically for deep learning, providing a 4×4 matrix array that processes calculations in parallel. For AI, the new Tensor cores provide a 5x performance improvement compared to using CUDA on the previous generation Pascal GPUs.
The Tesla V100 GPU will likely make its debut in the new $149,000 DGX-1 supercomputer which is scheduled to ship in the 3rd quarter of this year. When can we expect Volta-based GPUs for desktops? It’s difficult to say, especially with the supply of the HBM2 DRAM somewhat limited and the variety of timetables NVIDIA has followed in the past. Last year, the Pascal architecture was announced at GTC 2016 last May and the Titan X was announced the first week of August. Let’s hope for some good GPU news from NVIDIA around SIGGRAPH.
Deep Learning and VFX
While AI and deep learning seems to be getting much of the focus here at GTC, that’s not to say vfx and post are ignored. Far from it. The exhibit area has a large number of VR-centric companies on the floor and there is a large “VR Village” where attendees can demo various VR experiences.
The reality is that deep learning and neural networks will most certainly make an impact on the visual effects industry in the months and years ahead. Walking around FMX last week and chatting with attendees, machine learning and AI were a common talking point.
Here at GTC, a couple of hours after the keynote, Digital Domain’s Doug Roble gave a talk entitled “Exploring Machine Learning in Visual Effects”. He admitted that this is a new area of exploration in the visual effects field, but one he is greatly interested in. There are numerous opportunities to apply machine learning to vfx pipelines, from tasks such as denoising to character rigging to technical color correction and more.
Roble says his inspiration for exploring machine learning was a paper entitled Data-driven Fluid Simulations using Regression Forests (pdf download link). It was originally presented at SIGGRAPH Asia 2015 and presents an approach using machine learning to speed up simulations. It’s by no means a perfect approach, but a sensible path of exploration. Here’s a movie showing the results:
Digital Domain’s Lucio Moser is the primary architect of a paper that will be presented at SIGGRAPH 2017 entitled Masquerade: Fine-scale Details for Head Mounted Camera Motion Capture Data. The team started with work done by Bickel in 2008 and Bermano in 2014 and has adapted it to machine learning.
The basic concept is using the low resolution head mounted camera mocap dots to warp high resolution neutral poses of the actor’s face in order to achieve animation. One big problem with this approach are the missing details such as wrinkles and imperfections that make the result believable.
To work around this, the team at DD captured a high resolution mesh of the actor performing various actions on their capture stage. “From that,” says Roble, “we basically built a little machine learning process that said ‘if you see the actor’s face in this configuration then add in these details (from the high resolution captures).” So effectively the input to the machine learning was the low resolution version of the mesh and the output are the offsets to get it to the high resolution mesh. They found that this approach worked “really well, according to Roble, “It gave this really subtle performance that had a lot of smoothness, but had all the detail that we wanted.”
Roble’s overview of the paper was brief, so if you’d like to know more be sure to check out his presentation this summer at SIGGRAPH in Los Angeles.
As a frame of reference, another example of using machine learning is a paper by Jonathan Tompson, Kristofer Schlachter, Pablo Sprechmann, Ken Perlin entitled Accelerating Eulerian Fluid Simulation With Convolutional Networks (download pdf link).
These are just a few research examples of how the trends being seen here at GTC might impact the industry moving forward.